3. PyTorch scaling test
3.1. Scaling tests for PyTorch of ResNet152 on Imagenet
3.1.1. Introduction
This tutorial contains six training configurations: three baselines plus the itwinai trainer, which allows to switch from DDP, Horovod, and DeepSpeed in a simplified way.
The training scripts are:
ddp_trainer.py: baseline of distributed training with vanilla torch DDPdeepspeed_trainer.py: baseline of distributed training with vanilla Microsoft DeepSpeedhorovod_trainer.py: baseline of distributed training with vanilla Horovoditwinai_trainer.py: provides the same functionalities as all the above, using the unified itwinai’s distributed training interface.
Configuration files are stored into config/ folder. base.yaml provides the
configuration common to all training experiments, whereas ddp.yaml, deepspeed.yaml,
and horovod.yaml provide framework-specific configuration.
Thanks to itwinai.parser.ArgumentParser, the CLI arguments can be parsed from a list of
configuration files, while also allowing for online override.
Example:
# Rather than requiring a LONG list of inline configuration params...
python ddp_trainer.py --data-dir some/dir --log-int 10 --verbose --nworker 4 ...
# ...itwinai's ArgumentParser allows to load them from a set of configuration files
# with inline override, if needed
python ddp_trainer.py -c config/base.yaml -c config/ddp.yaml --log-int 42
3.1.2. Run a single training
Training runs are meant to be submitted via SLURM, from a unified job script file:
slurm.sh.
You can select the distributed training algorithm and provide the command to execute
setting SLURM environment variables using the --export option:
# Launch a distributed training setup with Torch DDP
export DIST_MODE="ddp"
export RUN_NAME="ddp-bl-imagenent"
export TRAINING_CMD="ddp_trainer.py -c config/base.yaml -c config/ddp.yaml"
export PYTHON_VENV="../../../envAI_hdfml"
export N=2 # Number of nodes
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
--nodes=$N slurm.sh
3.1.3. Run all training configurations
To run all training configurations you can use the runall.sh script, which provides
further insight how different training configurations can be launched using the same
SLURM job script.
bash runall.sh
And check the newly created jobs in the SLURM queue:
squeue -u YOUR_USERNAME
Each execution will generate a .csv file recording the time that each training epoch
took to complete. Below you can learn more on how to analyze these files to produce report.
3.1.4. Launch scaling test
Similarly to runall.sh, there is another script which is meant to launch a scalability
analysis experiment. This will launch all the training configuration for different number
of node allocations. By default it will run the same distributed trainings on 1, 2, 4, and
8 nodes. Each independent execution will generate a separate .csv file which can be
analyzed later to produce a scalability report.
Launch the scaling test:
bash scaling-test.sh
And check the newly created jobs in the SLURM queue:
squeue -u YOUR_USERNAME
3.1.5. Analyze results
Once all jobs have completed, you can automatically generate scalability report using itwinai’s CLI:
# First, activate you Python virtual environment
# For more info run
itwinai scalability-report --help
# Generate a scalability report
itwinai scalability-report --pattern="^epoch.+\.csv$" \
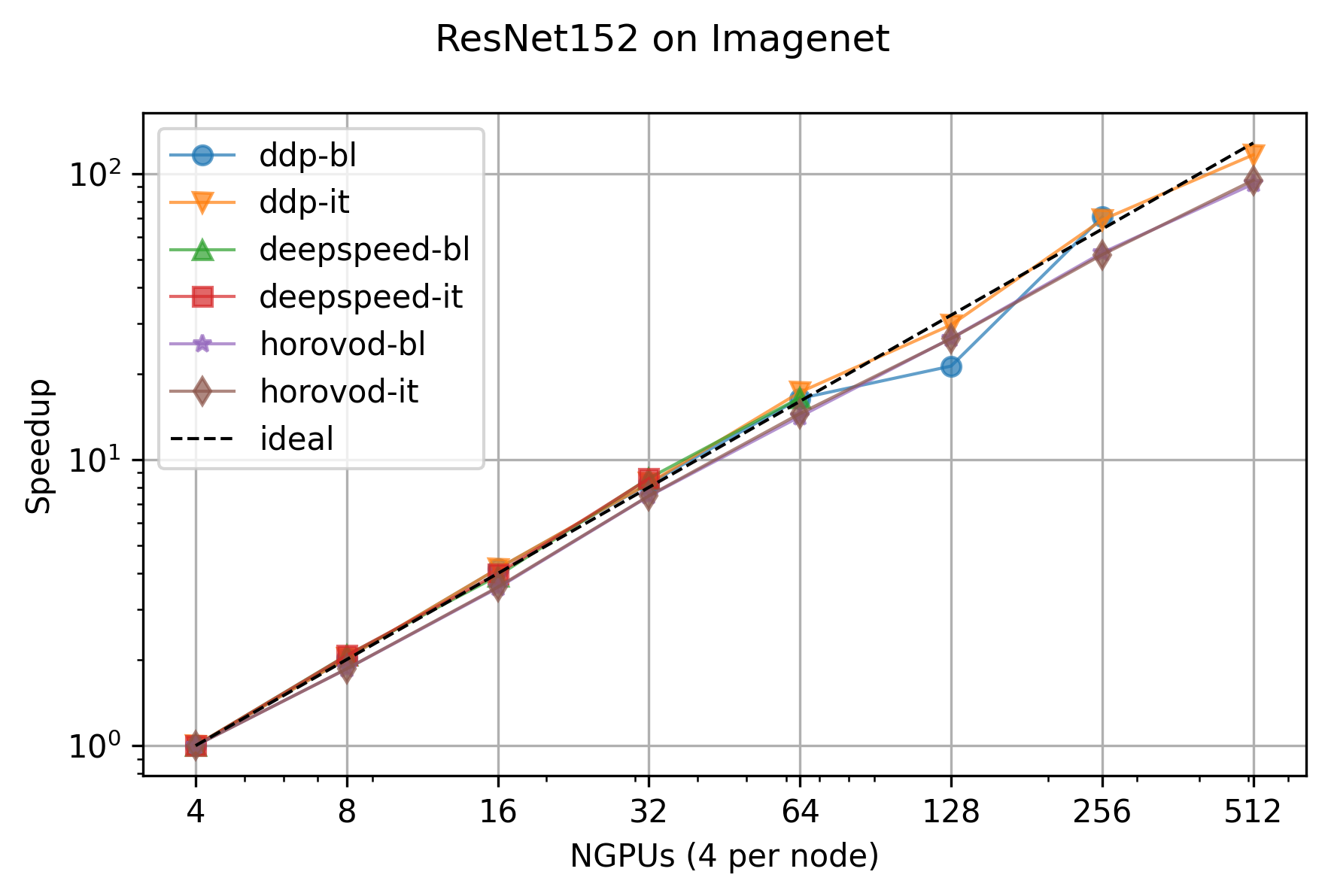
--plot-title "ResNet152 on Imagenet" --archive imagenet_results
The last command prints to terminal the average epoch time per training
configuration and per number of nodes, and it generated scaling test
analysis plot, which is saved as .png file. This command will also
create a .tar.gz archive of all the analyzed .csv files and
the generated plots, allowing you to easily organize different experiments
and reducing the risk of overwriting the logs generated during the scaling
test.
Example of scalability plot generated by itwinai scalability-report:
3.2. Configuration files
3.2.1. base.yaml
# Data and logging
data_dir: /p/scratch/intertwin/datasets/imagenet/ILSVRC2012/train/ # tmp_data/
log_int: 10
verbose: True
nworker: 4 # num workers dataloader
prefetch: 2
# Model
batch_size: 64 # micro batch size
epochs: 3
lr: 0.001
momentum: 0.5
shuff: False
# Reproducibility
rnd_seed: 10
3.2.2. ddp.yaml
backend: nccl
3.2.3. deepspeed.yaml
backend: nccl
3.2.4. horovod.yaml
fp16_allreduce: False
use_adasum: False
gradient_predivide_factor: 1.0
3.3. Training scripts and utils
3.3.1. ddp_trainer.py
"""
Scaling test of torch Distributed Data Parallel on Imagenet using Resnet.
"""
from typing import Optional
import argparse
import sys
import os
from timeit import default_timer as timer
import time
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
import torchvision
from itwinai.parser import ArgumentParser as ItAIArgumentParser
from itwinai.loggers import EpochTimeTracker
from itwinai.torch.reproducibility import (
seed_worker, set_seed
)
from utils import imagenet_dataset
def parse_params():
parser = ItAIArgumentParser(description='PyTorch Imagenet scaling test')
# Data and logging
parser.add_argument('--data-dir', default='./',
help=('location of the training dataset in the '
'local filesystem'))
parser.add_argument('--log-int', type=int, default=10,
help='log interval per training. Disabled if < 0.')
parser.add_argument('--verbose',
action=argparse.BooleanOptionalAction,
help='Print parsed arguments')
parser.add_argument('--nworker', type=int, default=0,
help=('number of workers in DataLoader '
'(default: 0 - only main)'))
parser.add_argument('--prefetch', type=int, default=2,
help='prefetch data in DataLoader (default: 2)')
# Model
parser.add_argument('--batch-size', type=int, default=64,
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=10,
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01,
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5,
help='momentum in SGD optimizer (default: 0.5)')
parser.add_argument('--shuff', action='store_true', default=False,
help='shuffle dataset (default: False)')
# Reproducibility
parser.add_argument('--rnd-seed', type=Optional[int], default=None,
help='seed integer for reproducibility (default: 0)')
# Distributed ML
parser.add_argument('--backend', type=str, default='nccl',
help='backend for parrallelisation (default: nccl)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables GPGPUs')
args = parser.parse_args()
if args.verbose:
args_list = [f"{key}: {val}" for key, val in args.items()]
print("PARSED ARGS:\n", '\n'.join(args_list))
return args
def train(model, device, train_loader, optimizer, epoch, grank, gwsize, args):
model.train()
t_list = []
loss_acc = 0
if grank == 0:
print("\n")
for batch_idx, (data, target) in enumerate(train_loader):
# if grank == 0:
# print(f"BS == DATA: {data.shape}, TARGET: {target.shape}")
t = timer()
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if grank == 0 and args.log_int > 0 and batch_idx % args.log_int == 0:
print(
f'Train epoch: {epoch} [{batch_idx * len(data)}/'
f'{len(train_loader.dataset) / gwsize} '
f'({100.0 * batch_idx / len(train_loader):.0f}%)]\t\tLoss: '
f'{loss.item():.6f}')
t_list.append(timer() - t)
loss_acc += loss.item()
if grank == 0:
print('TIMER: train time', sum(t_list) / len(t_list), 's')
return loss_acc
def main():
# Parse CLI args
args = parse_params()
# Check resources availability
use_cuda = not args.no_cuda and torch.cuda.is_available()
is_distributed = False
if use_cuda and torch.cuda.device_count() > 0:
is_distributed = True
# Limit # of CPU threads to be used per worker
# torch.set_num_threads(1)
# Start the timer for profiling
st = timer()
if is_distributed:
# Initializes the distributed backend which will
# take care of synchronizing the workers (nodes/GPUs)
dist.init_process_group(backend=args.backend)
# Set random seed for reproducibility
torch_prng = set_seed(args.rnd_seed, deterministic_cudnn=False)
if is_distributed:
# get job rank info - rank==0 master gpu
lwsize = torch.cuda.device_count() # local world size - per run
gwsize = dist.get_world_size() # global world size - per run
grank = dist.get_rank() # global rank - assign per run
lrank = dist.get_rank() % lwsize # local rank - assign per node
else:
# Use a single worker (either on GPU or CPU)
lwsize = 1
gwsize = 1
grank = 0
lrank = 0
if grank == 0:
print('TIMER: initialise:', timer()-st, 's')
print('DEBUG: local ranks:', lwsize, '/ global ranks:', gwsize)
print('DEBUG: sys.version:', sys.version)
print('DEBUG: args.data_dir:', args.data_dir)
print('DEBUG: args.log_int:', args.log_int)
print('DEBUG: args.nworker:', args.nworker)
print('DEBUG: args.prefetch:', args.prefetch)
print('DEBUG: args.batch_size:', args.batch_size)
print('DEBUG: args.epochs:', args.epochs)
print('DEBUG: args.lr:', args.lr)
print('DEBUG: args.momentum:', args.momentum)
print('DEBUG: args.shuff:', args.shuff)
print('DEBUG: args.rnd_seed:', args.rnd_seed)
print('DEBUG: args.backend:', args.backend)
print('DEBUG: args.no_cuda:', args.no_cuda, '\n')
# Encapsulate the model on the GPU assigned to the current process
device = torch.device('cuda' if use_cuda else 'cpu', lrank)
if use_cuda:
torch.cuda.set_device(lrank)
# Dataset
train_dataset = imagenet_dataset(args.data_dir)
if is_distributed:
# Distributed sampler restricts data loading to a subset of the dataset
# exclusive to the current process.
# `mun_replicas` and `rank` are automatically retrieved from
# the current distributed group.
train_sampler = DistributedSampler(
train_dataset, # num_replicas=gwsize, rank=grank,
shuffle=(args.shuff and args.rnd_seed is None)
)
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size,
sampler=train_sampler, num_workers=args.nworker, pin_memory=True,
persistent_workers=(args.nworker > 1),
prefetch_factor=args.prefetch, generator=torch_prng,
worker_init_fn=seed_worker
)
else:
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size, generator=torch_prng,
worker_init_fn=seed_worker
)
# Create CNN model
model = torchvision.models.resnet152().to(device)
# Distribute model to workers
if is_distributed:
model = nn.parallel.DistributedDataParallel(
model,
device_ids=[device],
output_device=device)
# Optimizer
optimizer = torch.optim.SGD(
model.parameters(), lr=args.lr, momentum=args.momentum)
# Start training loop
if grank == 0:
print('TIMER: broadcast:', timer()-st, 's')
print('\nDEBUG: start training')
print('--------------------------------------------------------')
nnod = os.environ.get('SLURM_NNODES', 'unk')
epoch_time_tracker = EpochTimeTracker(
series_name="ddp-bl",
csv_file=f"epochtime_ddp-bl_{nnod}N.csv"
)
et = timer()
start_epoch = 1
for epoch in range(start_epoch, args.epochs + 1):
lt = timer()
if is_distributed:
# Inform the sampler that a new epoch started: shuffle
# may be needed
train_sampler.set_epoch(epoch)
# Training
train(model, device, train_loader,
optimizer, epoch, grank, gwsize, args)
# Save first epoch timer
if epoch == start_epoch:
first_ep_t = timer()-lt
# Final epoch
if epoch + 1 == args.epochs:
train_loader.last_epoch = True
if grank == 0:
print('TIMER: epoch time:', timer() - lt, 's')
epoch_time_tracker.add_epoch_time(epoch-1, timer() - lt)
if is_distributed:
dist.barrier()
if grank == 0:
print('\n--------------------------------------------------------')
print('DEBUG: training results:\n')
print('TIMER: first epoch time:', first_ep_t, ' s')
print('TIMER: last epoch time:', timer() - lt, ' s')
print('TIMER: average epoch time:', (timer() - et)/args.epochs, ' s')
print('TIMER: total epoch time:', timer() - et, ' s')
if epoch > 1:
print('TIMER: total epoch-1 time:',
timer() - et - first_ep_t, ' s')
print('TIMER: average epoch-1 time:',
(timer() - et - first_ep_t) / (args.epochs - 1), ' s')
if use_cuda:
print('DEBUG: memory req:',
int(torch.cuda.memory_reserved(lrank) / 1024 / 1024), 'MB')
print('DEBUG: memory summary:\n\n',
torch.cuda.memory_summary(0))
print(f'TIMER: final time: {timer() - st} s\n')
time.sleep(1)
print(f"<Global rank: {grank}> - TRAINING FINISHED")
# Clean-up
if is_distributed:
dist.barrier()
dist.destroy_process_group()
if __name__ == "__main__":
main()
sys.exit()
3.3.2. deepspeed_trainer.py
"""
Scaling test of Microsoft Deepspeed on Imagenet using Resnet.
"""
from typing import Optional
import argparse
import sys
import os
from timeit import default_timer as timer
import time
import deepspeed
import torch
import torch.distributed as dist
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
import torchvision
from itwinai.parser import ArgumentParser as ItAIArgumentParser
from itwinai.loggers import EpochTimeTracker
from itwinai.torch.reproducibility import (
seed_worker, set_seed
)
from utils import imagenet_dataset
def parse_params():
parser = ItAIArgumentParser(description='PyTorch Imagenet scaling test')
# Data and logging
parser.add_argument('--data-dir', default='./',
help=('location of the training dataset in the '
'local filesystem'))
parser.add_argument('--log-int', type=int, default=10,
help='log interval per training. Disabled if < 0.')
parser.add_argument('--verbose',
action=argparse.BooleanOptionalAction,
help='Print parsed arguments')
parser.add_argument('--nworker', type=int, default=0,
help=('number of workers in DataLoader '
'(default: 0 - only main)'))
parser.add_argument('--prefetch', type=int, default=2,
help='prefetch data in DataLoader (default: 2)')
# Model
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5,
help='momentum in SGD optimizer (default: 0.5)')
parser.add_argument('--shuff', action='store_true', default=False,
help='shuffle dataset (default: False)')
# Reproducibility
parser.add_argument('--rnd-seed', type=Optional[int], default=None,
help='seed integer for reproducibility (default: 0)')
# Distributed ML
parser.add_argument('--backend', type=str, default='nccl', metavar='N',
help='backend for parallelization (default: nccl)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables GPGPUs')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
# parse to deepspeed
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
if args.verbose:
args_list = [f"{key}: {val}" for key, val in args.items()]
print("PARSED ARGS:\n", '\n'.join(args_list))
return args
def train(args, model, train_loader, optimizer, epoch, grank, gwsize):
device = model.local_rank
t_list = []
loss_acc = 0
if grank == 0:
print("\n")
for batch_idx, (data, target) in enumerate(train_loader):
# if grank == 0:
# print(f"BS == DATA: {data.shape}, TARGET: {target.shape}")
t = timer()
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if args.log_int > 0 and batch_idx % args.log_int == 0 and grank == 0:
print(
f'Train epoch: {epoch} [{batch_idx * len(data)}/'
f'{len(train_loader.dataset) / gwsize} '
f'({100.0 * batch_idx * len(data) / len(train_loader):.0f}%)]'
f'\t\tLoss: {loss.item():.6f}')
t_list.append(timer() - t)
loss_acc += loss.item()
if grank == 0:
print('TIMER: train time', sum(t_list) / len(t_list), 's')
return loss_acc
def main():
# Parse CLI args
args = parse_params()
# Check resources availability
use_cuda = not args.no_cuda and torch.cuda.is_available()
is_distributed = False
if use_cuda and torch.cuda.device_count() > 0:
is_distributed = True
# Limit # of CPU threads to be used per worker
# torch.set_num_threads(1)
# Start the timer for profiling
st = timer()
# Initializes the distributed backend
if is_distributed:
deepspeed.init_distributed(dist_backend=args.backend)
# Set random seed for reproducibility
torch_prng = set_seed(args.rnd_seed, deterministic_cudnn=False)
if is_distributed:
# Get job rank info - rank==0 master gpu
gwsize = dist.get_world_size() # global world size - per run
lwsize = torch.cuda.device_count() # local world size - per node
grank = dist.get_rank() # global rank - assign per run
lrank = dist.get_rank() % lwsize # local rank - assign per node
else:
# Use a single worker (either on GPU or CPU)
lwsize = 1
gwsize = 1
grank = 0
lrank = 0
if grank == 0:
print('TIMER: initialise:', timer()-st, 's')
print('DEBUG: local ranks:', lwsize, '/ global ranks:', gwsize)
print('DEBUG: sys.version:', sys.version)
print('DEBUG: args.data_dir:', args.data_dir)
print('DEBUG: args.log_int:', args.log_int)
print('DEBUG: args.nworker:', args.nworker)
print('DEBUG: args.prefetch:', args.prefetch)
print('DEBUG: args.batch_size:', args.batch_size)
print('DEBUG: args.epochs:', args.epochs)
print('DEBUG: args.lr:', args.lr)
print('DEBUG: args.momentum:', args.momentum)
print('DEBUG: args.shuff:', args.shuff)
print('DEBUG: args.rnd_seed:', args.rnd_seed)
print('DEBUG: args.backend:', args.backend)
print('DEBUG: args.local_rank:', args.local_rank)
print('DEBUG: args.no_cuda:', args.no_cuda, '\n')
# Encapsulate the model on the GPU assigned to the current process
if use_cuda:
torch.cuda.set_device(lrank)
# Read training dataset
train_dataset = imagenet_dataset(args.data_dir)
if is_distributed:
# Distributed sampler restricts data loading to a subset of the dataset
# exclusive to the current process.
# `mun_replicas` and `rank` are automatically retrieved from
# the current distributed group.
train_sampler = DistributedSampler(
train_dataset, # num_replicas=gwsize, rank=grank,
shuffle=(args.shuff and args.rnd_seed is None)
)
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size,
sampler=train_sampler, num_workers=args.nworker, pin_memory=True,
persistent_workers=(args.nworker > 1),
prefetch_factor=args.prefetch, generator=torch_prng,
worker_init_fn=seed_worker
)
else:
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size, generator=torch_prng,
worker_init_fn=seed_worker
)
# Create CNN model
model = torchvision.models.resnet152()
# Initialize DeepSpeed and get:
# 1) Distributed model
# 2) DeepSpeed optimizer
# 3) Distributed data loader
deepspeed_config = {
"train_micro_batch_size_per_gpu": args.batch_size, # redundant
"optimizer": {
"type": "SGD",
"params": {
"lr": args.lr,
"momentum": args.momentum
}
},
"fp16": {
"enabled": False
},
"zero_optimization": False
}
distrib_model, optimizer, deepspeed_train_loader, _ = deepspeed.initialize(
args=args, model=model, model_parameters=model.parameters(),
training_data=train_dataset, config_params=deepspeed_config)
# Start training loop
if grank == 0:
print('TIMER: broadcast:', timer()-st, 's')
print('\nDEBUG: start training')
print('--------------------------------------------------------')
nnod = os.environ.get('SLURM_NNODES', 'unk')
epoch_time_tracker = EpochTimeTracker(
series_name="deepspeed-bl",
csv_file=f"epochtime_deepspeed-bl_{nnod}N.csv"
)
et = timer()
start_epoch = 1
for epoch in range(start_epoch, args.epochs + 1):
lt = timer()
if is_distributed:
# Inform the sampler that a new epoch started: shuffle
# may be needed
train_sampler.set_epoch(epoch)
# Training
train(args, distrib_model, train_loader,
optimizer, epoch, grank, gwsize)
# Save first epoch timer
if epoch == start_epoch:
first_ep_t = timer()-lt
# Final epoch
if epoch + 1 == args.epochs:
train_loader.last_epoch = True
if grank == 0:
print('TIMER: epoch time:', timer()-lt, 's')
epoch_time_tracker.add_epoch_time(epoch-1, timer()-lt)
if is_distributed:
dist.barrier()
if grank == 0:
print('\n--------------------------------------------------------')
print('DEBUG: results:\n')
print('TIMER: first epoch time:', first_ep_t, ' s')
print('TIMER: last epoch time:', timer()-lt, ' s')
print('TIMER: average epoch time:', (timer()-et)/args.epochs, ' s')
print('TIMER: total epoch time:', timer()-et, ' s')
if epoch > 1:
print('TIMER: total epoch-1 time:',
timer()-et-first_ep_t, ' s')
print('TIMER: average epoch-1 time:',
(timer()-et-first_ep_t)/(args.epochs-1), ' s')
if use_cuda:
print('DEBUG: memory req:',
int(torch.cuda.memory_reserved(lrank)/1024/1024), 'MB')
print('DEBUG: memory summary:\n\n',
torch.cuda.memory_summary(0))
print(f'TIMER: final time: {timer()-st} s\n')
time.sleep(1)
print(f"<Global rank: {grank}> - TRAINING FINISHED")
# Clean-up
if is_distributed:
deepspeed.sys.exit()
if __name__ == "__main__":
main()
sys.exit()
3.3.3. horovod_trainer.py
"""
Scaling test of Horovod on Imagenet using Resnet.
"""
from typing import Optional
import argparse
import os
import sys
from timeit import default_timer as timer
import time
import torch
# import torch.multiprocessing as mp
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
import horovod.torch as hvd
import torchvision
from itwinai.parser import ArgumentParser as ItAIArgumentParser
from itwinai.loggers import EpochTimeTracker
from itwinai.torch.reproducibility import (
seed_worker, set_seed
)
from utils import imagenet_dataset
def parse_params():
parser = ItAIArgumentParser(description='PyTorch Imagenet Example')
# Data and logging
parser.add_argument('--data-dir', default='./',
help=('location of the training dataset in the '
'local filesystem'))
parser.add_argument('--log-int', type=int, default=100,
help=('#batches to wait before logging training '
'status. Disabled if < 0.'))
parser.add_argument('--verbose',
action=argparse.BooleanOptionalAction,
help='Print parsed arguments')
parser.add_argument('--nworker', type=int, default=0,
help=('number of workers in DataLoader '
'(default: 0 - only main)'))
parser.add_argument('--prefetch', type=int, default=2,
help='prefetch data in DataLoader (default: 2)')
# Model
parser.add_argument('--batch-size', type=int, default=64,
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=10,
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01,
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5,
help='SGD momentum (default: 0.5)')
parser.add_argument('--shuff', action='store_true', default=False,
help='shuffle dataset (default: False)')
# Reproducibility
parser.add_argument('--rnd-seed', type=Optional[int], default=None,
help='seed integer for reproducibility (default: 0)')
# Distributed ML
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--fp16-allreduce', action='store_true', default=False,
help='use fp16 compression during allreduce')
parser.add_argument('--use-adasum', action='store_true', default=False,
help='use adasum algorithm to do reduction')
parser.add_argument('--gradient-predivide-factor', type=float, default=1.0,
help=('apply gradient pre-divide factor in optimizer '
'(default: 1.0)'))
args = parser.parse_args()
if args.verbose:
args_list = [f"{key}: {val}" for key, val in args.items()]
print("PARSED ARGS:\n", '\n'.join(args_list))
return args
def train(
model, optimizer, train_sampler, train_loader,
args, use_cuda, epoch, grank
):
model.train()
t_list = []
loss_acc = 0
if grank == 0:
print("\n")
for batch_idx, (data, target) in enumerate(train_loader):
# if hvd.local_rank() == 0 and hvd.rank() == 0:
# print(f"BS == DATA: {data.shape}, TARGET: {target.shape}")
t = timer()
if use_cuda:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if grank == 0 and args.log_int > 0 and batch_idx % args.log_int == 0:
# Use train_sampler to determine the number of examples in
# this worker's partition
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_sampler),
100. * batch_idx / len(train_loader), loss.item()))
t_list.append(timer() - t)
loss_acc += loss.item()
if grank == 0:
print('TIMER: train time', sum(t_list) / len(t_list), 's')
return loss_acc
def main():
# Parse CLI args
args = parse_params()
# Check resources availability
use_cuda = not args.no_cuda and torch.cuda.is_available()
is_distributed = False
if use_cuda and torch.cuda.device_count() > 0:
is_distributed = True
# Start the time.time for profiling
st = timer()
if is_distributed:
# Initializes the distributed backend which will
# take care of synchronizing the workers (nodes/GPUs)
hvd.init()
# Set random seed for reproducibility
torch_prng = set_seed(args.rnd_seed, deterministic_cudnn=False)
# is_main_worker = True
# if is_distributed and (hvd.rank() != 0 or hvd.local_rank() != 0):
# is_main_worker = False
# Get local rank
if is_distributed:
lrank = hvd.local_rank()
grank = hvd.rank()
gwsize = hvd.size()
lwsize = torch.cuda.device_count()
else:
# Use a single worker (either on GPU or CPU)
lrank = 0
grank = 0
gwsize = 1
lwsize = 1
if grank == 0:
print('TIMER: initialise:', timer()-st, 's')
print('DEBUG: local ranks:', lwsize, '/ global ranks:', gwsize)
print('DEBUG: sys.version:', sys.version)
print('DEBUG: args.data_dir:', args.data_dir)
print('DEBUG: args.log_int:', args.log_int)
print('DEBUG: args.nworker:', args.nworker)
print('DEBUG: args.prefetch:', args.prefetch)
print('DEBUG: args.batch_size:', args.batch_size)
print('DEBUG: args.epochs:', args.epochs)
print('DEBUG: args.lr:', args.lr)
print('DEBUG: args.momentum:', args.momentum)
print('DEBUG: args.shuff:', args.shuff)
print('DEBUG: args.rnd_seed:', args.rnd_seed)
print('DEBUG: args.no_cuda:', args.no_cuda)
print('DEBUG: args.fp16_allreduce:', args.fp16_allreduce)
print('DEBUG: args.use_adasum:', args.use_adasum)
print('DEBUG: args.gradient_predivide_factor:',
args.gradient_predivide_factor)
if use_cuda:
print('DEBUG: torch.cuda.is_available():',
torch.cuda.is_available())
print('DEBUG: torch.cuda.current_device():',
torch.cuda.current_device())
print('DEBUG: torch.cuda.device_count():',
torch.cuda.device_count())
print('DEBUG: torch.cuda.get_device_properties(hvd.local_rank()):',
torch.cuda.get_device_properties(hvd.local_rank()))
if use_cuda:
# Pin GPU to local rank
torch.cuda.set_device(lrank)
# Limit # of CPU threads to be used per worker
# torch.set_num_threads(1)
# Dataset
train_dataset = imagenet_dataset(args.data_dir)
# kwargs = {}
# # When supported, use 'forkserver' to spawn dataloader workers instead...
# # issues with Infiniband implementations that are not fork-safe
# if (args.nworker > 0 and hasattr(mp, '_supports_context')
# and
# mp._supports_context and
# 'forkserver' in mp.get_all_start_methods()):
# kwargs['multiprocessing_context'] = 'forkserver'
if is_distributed:
# Use DistributedSampler to partition the training data
# Since Horovod is not based on torch.distributed,
# `num_replicas` and `rank` cannot be retrieved from the
# current distributed group, thus they need to be provided explicitly.
train_sampler = DistributedSampler(
train_dataset, num_replicas=gwsize, rank=grank,
shuffle=(args.shuff and args.rnd_seed is None)
)
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size,
sampler=train_sampler, num_workers=args.nworker, pin_memory=True,
persistent_workers=(args.nworker > 1),
prefetch_factor=args.prefetch, generator=torch_prng,
worker_init_fn=seed_worker
) # , **kwargs)
else:
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size, generator=torch_prng,
worker_init_fn=seed_worker
) # , **kwargs)
# Create CNN model
model = torchvision.models.resnet152()
if use_cuda:
model.cuda()
if is_distributed:
# By default, Adasum doesn't need scaling up learning rate
lr_scaler = hvd.size() if not args.use_adasum else 1
# If using GPU Adasum allreduce, scale learning rate by local_size
if args.use_adasum and hvd.nccl_built():
lr_scaler = hvd.local_size()
# Scale learning rate by lr_scaler
args.lr *= lr_scaler
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum)
if is_distributed:
# Broadcast parameters & optimizer state
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
# Compression algorithm
compression = (
hvd.Compression.fp16 if args.fp16_allreduce
else hvd.Compression.none
)
# Wrap optimizer with DistributedOptimizer
optimizer = hvd.DistributedOptimizer(
optimizer,
named_parameters=model.named_parameters(),
compression=compression,
op=hvd.Adasum if args.use_adasum else hvd.Average,
gradient_predivide_factor=args.gradient_predivide_factor)
if grank == 0:
print('TIMER: broadcast:', timer()-st, 's')
print('\nDEBUG: start training')
print('--------------------------------------------------------')
nnod = os.environ.get('SLURM_NNODES', 'unk')
epoch_time_tracker = EpochTimeTracker(
series_name="horovod-bl",
csv_file=f"epochtime_horovod-bl_{nnod}N.csv"
)
et = timer()
start_epoch = 1
for epoch in range(start_epoch, args.epochs + 1):
lt = timer()
if is_distributed:
# Inform the sampler that a new epoch started: shuffle
# may be needed
train_sampler.set_epoch(epoch)
# Training
train(model, optimizer, train_sampler,
train_loader, args, use_cuda, epoch, grank)
# Save first epoch timer
if epoch == start_epoch:
first_ep_t = timer()-lt
# Final epoch
if epoch + 1 == args.epochs:
train_loader.last_epoch = True
if grank == 0:
print('TIMER: epoch time:', timer()-lt, 's')
epoch_time_tracker.add_epoch_time(epoch-1, timer()-lt)
if grank == 0:
print('\n--------------------------------------------------------')
print('DEBUG: training results:\n')
print('TIMER: first epoch time:', first_ep_t, ' s')
print('TIMER: last epoch time:', timer()-lt, 's')
print('TIMER: average epoch time:', (timer()-et)/args.epochs, ' s')
print('TIMER: total epoch time:', timer()-et, ' s')
if epoch > 1:
print('TIMER: total epoch-1 time:',
timer()-et-first_ep_t, ' s')
print('TIMER: average epoch-1 time:',
(timer()-et-first_ep_t)/(args.epochs-1), ' s')
if use_cuda:
print('DEBUG: memory req:',
int(torch.cuda.memory_reserved(lrank)/1024/1024), 'MB')
print('DEBUG: memory summary:\n\n',
torch.cuda.memory_summary(0))
print(f'TIMER: final time: {timer()-st} s\n')
time.sleep(1)
print(f"<Hvd rank: {hvd.rank()}> - TRAINING FINISHED")
if __name__ == "__main__":
main()
sys.exit()
3.3.4. itwinai_trainer.py
"""
Show how to use DDP, Horovod and DeepSpeed strategies interchangeably
with a large neural network trained on Imagenet dataset, showing how
to use checkpoints.
"""
from typing import Optional
import os
import argparse
import sys
from timeit import default_timer as timer
import time
import torch
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
import deepspeed
import horovod.torch as hvd
from itwinai.torch.distributed import (
TorchDistributedStrategy,
TorchDDPStrategy,
HorovodStrategy,
DeepSpeedStrategy,
)
from itwinai.parser import ArgumentParser as ItAIArgumentParser
from itwinai.loggers import EpochTimeTracker
from itwinai.torch.reproducibility import (
seed_worker, set_seed
)
from utils import imagenet_dataset
def parse_params() -> argparse.Namespace:
"""
Parse CLI args, which can also be loaded from a configuration file
using the --config flag:
>>> train.py --strategy ddp --config base-config.yaml --config foo.yaml
"""
parser = ItAIArgumentParser(description='PyTorch Imagenet Example')
# Distributed ML strategy
parser.add_argument(
"--strategy", "-s", type=str,
choices=['ddp', 'horovod', 'deepspeed'],
default='ddp'
)
# Data and logging
parser.add_argument('--data-dir', default='./',
help=('location of the training dataset in the local '
'filesystem'))
parser.add_argument('--log-int', type=int, default=10,
help='log interval per training')
parser.add_argument('--verbose',
action=argparse.BooleanOptionalAction,
help='Print parsed arguments')
parser.add_argument('--nworker', type=int, default=0,
help=('number of workers in DataLoader (default: 0 -'
' only main)'))
parser.add_argument('--prefetch', type=int, default=2,
help='prefetch data in DataLoader (default: 2)')
# Model
parser.add_argument('--batch-size', type=int, default=64,
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=10,
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01,
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5,
help='momentum in SGD optimizer (default: 0.5)')
parser.add_argument('--shuff', action='store_true', default=False,
help='shuffle dataset (default: False)')
# Reproducibility
parser.add_argument('--rnd-seed', type=Optional[int], default=None,
help='seed integer for reproducibility (default: 0)')
# Distributed ML
parser.add_argument('--backend', type=str, default='nccl',
help='backend for parrallelisation (default: nccl)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables GPGPUs')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
# Horovod
parser.add_argument('--fp16-allreduce', action='store_true', default=False,
help='use fp16 compression during allreduce')
parser.add_argument('--use-adasum', action='store_true', default=False,
help='use adasum algorithm to do reduction')
parser.add_argument('--gradient-predivide-factor', type=float, default=1.0,
help=('apply gradient pre-divide factor in optimizer '
'(default: 1.0)'))
# DeepSpeed
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
if args.verbose:
args_list = [f"{key}: {val}" for key, val in args.items()]
print("PARSED ARGS:\n", '\n'.join(args_list))
return args
def train(
model, device, train_loader, optimizer, epoch,
strategy: TorchDistributedStrategy, args
):
"""
Training function, representing an epoch.
"""
model.train()
t_list = []
loss_acc = 0
gwsize = strategy.global_world_size()
if strategy.is_main_worker:
print("\n")
for batch_idx, (data, target) in enumerate(train_loader):
t = timer()
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (strategy.is_main_worker and args.log_int > 0
and batch_idx % args.log_int == 0):
print(
f'Train epoch: {epoch} '
f'[{batch_idx * len(data)}/{len(train_loader.dataset)/gwsize} '
f'({100.0 * batch_idx / len(train_loader):.0f}%)]\t\t'
f'Loss: {loss.item():.6f}')
t_list.append(timer() - t)
loss_acc += loss.item()
if strategy.is_main_worker:
print('TIMER: train time', sum(t_list) / len(t_list), 's')
return loss_acc
def main():
# Parse CLI args
args = parse_params()
# Instantiate Strategy
if args.strategy == 'ddp':
if (not torch.cuda.is_available()
or not torch.cuda.device_count() > 1):
raise RuntimeError('Resources unavailable')
strategy = TorchDDPStrategy(backend=args.backend)
distribute_kwargs = {}
elif args.strategy == 'horovod':
strategy = HorovodStrategy()
distribute_kwargs = dict(
compression=(
hvd.Compression.fp16 if args.fp16_allreduce
else hvd.Compression.none
),
op=hvd.Adasum if args.use_adasum else hvd.Average,
gradient_predivide_factor=args.gradient_predivide_factor
)
elif args.strategy == 'deepspeed':
strategy = DeepSpeedStrategy(backend=args.backend)
distribute_kwargs = dict(
config_params=dict(train_micro_batch_size_per_gpu=args.batch_size)
)
else:
raise NotImplementedError(
f"Strategy {args.strategy} is not recognized/implemented.")
strategy.init()
# Check resources availability
use_cuda = not args.no_cuda and torch.cuda.is_available()
is_distributed = False
if use_cuda and torch.cuda.device_count() > 0:
is_distributed = True
# Limit # of CPU threads to be used per worker
# torch.set_num_threads(1)
# Start the timer for profiling
st = timer()
# Set random seed for reproducibility
torch_prng = set_seed(args.rnd_seed, deterministic_cudnn=False)
# Get job rank info - rank==0 master gpu
if is_distributed:
# local world size - per node
lwsize = strategy.local_world_size() # local world size - per run
gwsize = strategy.global_world_size() # global world size - per run
grank = strategy.global_rank() # global rank - assign per run
lrank = strategy.local_rank() # local rank - assign per node
else:
# Use a single worker (either on GPU or CPU)
lwsize = 1
gwsize = 1
grank = 0
lrank = 0
if strategy.is_main_worker:
print('TIMER: initialise:', timer()-st, 's')
print('DEBUG: local ranks:', lwsize, '/ global ranks:', gwsize)
print('DEBUG: sys.version:', sys.version)
print('DEBUG: args.data_dir:', args.data_dir)
print('DEBUG: args.log_int:', args.log_int)
print('DEBUG: args.nworker:', args.nworker)
print('DEBUG: args.prefetch:', args.prefetch)
print('DEBUG: args.batch_size:', args.batch_size)
print('DEBUG: args.epochs:', args.epochs)
print('DEBUG: args.lr:', args.lr)
print('DEBUG: args.momentum:', args.momentum)
print('DEBUG: args.shuff:', args.shuff)
print('DEBUG: args.rnd_seed:', args.rnd_seed)
print('DEBUG: args.backend:', args.backend)
print('DEBUG: args.no_cuda:', args.no_cuda, '\n')
# Encapsulate the model on the GPU assigned to the current process
device = torch.device(
strategy.device() if use_cuda
else 'cpu')
if use_cuda:
torch.cuda.set_device(lrank)
# Dataset
train_dataset = imagenet_dataset(args.data_dir)
if is_distributed:
# Distributed sampler restricts data loading to a subset of the dataset
# exclusive to the current process.
train_sampler = DistributedSampler(
train_dataset, num_replicas=gwsize, rank=grank,
shuffle=(args.shuff and args.rnd_seed is None)
)
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size,
sampler=train_sampler, num_workers=args.nworker, pin_memory=True,
persistent_workers=(args.nworker > 1),
prefetch_factor=args.prefetch, generator=torch_prng,
worker_init_fn=seed_worker
)
else:
train_loader = DataLoader(
train_dataset, batch_size=args.batch_size, generator=torch_prng,
worker_init_fn=seed_worker
)
# Create CNN model: resnet 50, resnet101, resnet152
model = torchvision.models.resnet152()
# Optimizer
optimizer = torch.optim.SGD(
model.parameters(), lr=args.lr, momentum=args.momentum)
if is_distributed:
distrib_model, optimizer, _ = strategy.distributed(
model, optimizer, lr_scheduler=None, **distribute_kwargs
)
# Start training loop
if strategy.is_main_worker:
print('TIMER: broadcast:', timer()-st, 's')
print('\nDEBUG: start training')
print('--------------------------------------------------------')
nnod = os.environ.get('SLURM_NNODES', 'unk')
s_name = f"{args.strategy}-it"
epoch_time_tracker = EpochTimeTracker(
series_name=s_name,
csv_file=f"epochtime_{s_name}_{nnod}N.csv"
)
et = timer()
start_epoch = 1
for epoch in range(start_epoch, args.epochs + 1):
lt = timer()
if is_distributed:
# Inform the sampler that a new epoch started: shuffle
# may be needed
train_sampler.set_epoch(epoch)
# Training
train(
model=distrib_model,
device=device,
train_loader=train_loader,
optimizer=optimizer,
epoch=epoch,
strategy=strategy,
args=args
)
# Save first epoch timer
if epoch == start_epoch:
first_ep_t = timer()-lt
# Final epoch
if epoch + 1 == args.epochs:
train_loader.last_epoch = True
if strategy.is_main_worker:
print('TIMER: epoch time:', timer()-lt, 's')
epoch_time_tracker.add_epoch_time(epoch-1, timer()-lt)
if strategy.is_main_worker:
print('\n--------------------------------------------------------')
print('DEBUG: training results:\n')
print('TIMER: first epoch time:', first_ep_t, ' s')
print('TIMER: last epoch time:', timer()-lt, ' s')
print('TIMER: average epoch time:', (timer()-et)/args.epochs, ' s')
print('TIMER: total epoch time:', timer()-et, ' s')
if epoch > 1:
print('TIMER: total epoch-1 time:',
timer()-et-first_ep_t, ' s')
print('TIMER: average epoch-1 time:',
(timer()-et-first_ep_t)/(args.epochs-1), ' s')
if use_cuda:
print('DEBUG: memory req:',
int(torch.cuda.memory_reserved(lrank)/1024/1024), 'MB')
print('DEBUG: memory summary:\n\n',
torch.cuda.memory_summary(0))
print(f'TIMER: final time: {timer()-st} s\n')
time.sleep(1)
print(f"<Global rank: {strategy.global_rank()}> - TRAINING FINISHED")
# Clean-up
if is_distributed:
strategy.clean_up()
if __name__ == "__main__":
main()
sys.exit()
3.3.5. utils.py
from torchvision import datasets, transforms
def imagenet_dataset(data_root: str):
"""Create a torch dataset object for Imagenet."""
transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(degrees=45),
transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
imagenet = datasets.ImageFolder(
root=data_root,
transform=transform
)
return imagenet
3.3.6. runall.sh
#!/bin/bash
# Run all versions of distributed ML version
# $1 (Optional[int]): number of nodes. Default: 2
# $2 (Optional[str]): timeout. Default: "00:30:00"
if [ -z "$1" ] ; then
N=2
else
N=$1
fi
if [ -z "$2" ] ; then
T="00:30:00"
else
T=$2
fi
# Common options
CMD="--nodes=$N --time=$T --account=intertwin --partition=batch slurm.sh"
PYTHON_VENV="../../../envAI_hdfml"
echo "Distributing training over $N nodes. Timeout set to: $T"
# Clear SLURM logs (*.out and *.err files)
rm -rf logs_slurm
mkdir logs_slurm
rm -rf logs_torchrun
# Clear scaling test logs
rm *.csv # *checkpoint.pth.tar
# DDP baseline
DIST_MODE="ddp"
RUN_NAME="ddp-bl-imagenent"
TRAINING_CMD="ddp_trainer.py -c config/base.yaml -c config/ddp.yaml"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
# DeepSpeed baseline
DIST_MODE="deepspeed"
RUN_NAME="deepspeed-bl-imagenent"
TRAINING_CMD="deepspeed_trainer.py -c config/base.yaml -c config/deepspeed.yaml"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
# Horovod baseline
DIST_MODE="horovod"
RUN_NAME="horovod-bl-imagenent"
TRAINING_CMD="horovod_trainer.py -c config/base.yaml -c config/horovod.yaml"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
# DDP itwinai
DIST_MODE="ddp"
RUN_NAME="ddp-itwinai-imagenent"
TRAINING_CMD="itwinai_trainer.py -c config/base.yaml -c config/ddp.yaml -s ddp"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
# DeepSpeed itwinai
DIST_MODE="deepspeed"
RUN_NAME="deepspeed-itwinai-imagenent"
TRAINING_CMD="itwinai_trainer.py -c config/base.yaml -c config/deepspeed.yaml -s deepspeed"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
# Horovod itwinai
DIST_MODE="horovod"
RUN_NAME="horovod-itwinai-imagenent"
TRAINING_CMD="itwinai_trainer.py -c config/base.yaml -c config/horovod.yaml -s horovod"
sbatch --export=ALL,DIST_MODE="$DIST_MODE",RUN_NAME="$RUN_NAME",TRAINING_CMD="$TRAINING_CMD",PYTHON_VENV="$PYTHON_VENV" \
--job-name="$RUN_NAME-n$N" \
--output="logs_slurm/job-$RUN_NAME-n$N.out" \
--error="logs_slurm/job-$RUN_NAME-n$N.err" \
$CMD
3.3.7. scaling-test.sh
#!/bin/bash
rm *checkpoint.pth.tar *.out *.err *.csv
timeout="03:30:00"
for N in 1 2 4 8 16 32 64 128
do
bash runall.sh $N $timeout
echo
done
3.3.8. slurm.sh
#!/bin/bash
# SLURM jobscript for JSC systems
# Job configuration
#SBATCH --job-name=distributed_training
#SBATCH --account=intertwin
#SBATCH --mail-user=
#SBATCH --mail-type=ALL
#SBATCH --output=job.out
#SBATCH --error=job.err
#SBATCH --time=00:30:00
# Resources allocation
#SBATCH --partition=batch
#SBATCH --nodes=2
#SBATCH --gpus-per-node=4
#SBATCH --cpus-per-gpu=4
#SBATCH --exclusive
# gres options have to be disabled for deepv
#SBATCH --gres=gpu:4
# Load environment modules
ml Stages/2024 GCC OpenMPI CUDA/12 MPI-settings/CUDA Python HDF5 PnetCDF libaio mpi4py
# Job info
echo "DEBUG: TIME: $(date)"
sysN="$(uname -n | cut -f2- -d.)"
sysN="${sysN%%[0-9]*}"
echo "Running on system: $sysN"
echo "DEBUG: EXECUTE: $EXEC"
echo "DEBUG: SLURM_SUBMIT_DIR: $SLURM_SUBMIT_DIR"
echo "DEBUG: SLURM_JOB_ID: $SLURM_JOB_ID"
echo "DEBUG: SLURM_JOB_NODELIST: $SLURM_JOB_NODELIST"
echo "DEBUG: SLURM_NNODES: $SLURM_NNODES"
echo "DEBUG: SLURM_NTASKS: $SLURM_NTASKS"
echo "DEBUG: SLURM_TASKS_PER_NODE: $SLURM_TASKS_PER_NODE"
echo "DEBUG: SLURM_SUBMIT_HOST: $SLURM_SUBMIT_HOST"
echo "DEBUG: SLURMD_NODENAME: $SLURMD_NODENAME"
echo "DEBUG: CUDA_VISIBLE_DEVICES: $CUDA_VISIBLE_DEVICES"
if [ "$DEBUG" = true ] ; then
echo "DEBUG: NCCL_DEBUG=INFO"
export NCCL_DEBUG=INFO
fi
echo
# Setup env for distributed ML
export CUDA_VISIBLE_DEVICES="0,1,2,3"
export OMP_NUM_THREADS=1
if [ "$SLURM_CPUS_PER_GPU" -gt 0 ] ; then
export OMP_NUM_THREADS=$SLURM_CPUS_PER_GPU
fi
# Env vairables check
if [ -z "$DIST_MODE" ]; then
>&2 echo "ERROR: env variable DIST_MODE is not set. Allowed values are 'horovod', 'ddp' or 'deepspeed'"
exit 1
fi
if [ -z "$RUN_NAME" ]; then
>&2 echo "WARNING: env variable RUN_NAME is not set. It's a way to identify some specific run of an experiment."
RUN_NAME=$DIST_MODE
fi
if [ -z "$TRAINING_CMD" ]; then
>&2 echo "ERROR: env variable TRAINING_CMD is not set. It's the python command to execute."
exit 1
fi
if [ -z "$PYTHON_VENV" ]; then
>&2 echo "WARNING: env variable PYTHON_VENV is not set. It's the path to a python virtual environment."
else
# Activate Python virtual env
source $PYTHON_VENV/bin/activate
fi
# Get GPUs info per node
srun --cpu-bind=none --ntasks-per-node=1 bash -c 'echo -e "NODE hostname: $(hostname)\n$(nvidia-smi)\n\n"'
# Launch training
if [ "$DIST_MODE" == "ddp" ] ; then
echo "DDP training: $TRAINING_CMD"
srun --cpu-bind=none --ntasks-per-node=1 \
bash -c "torchrun \
--log_dir='logs_torchrun' \
--nnodes=$SLURM_NNODES \
--nproc_per_node=$SLURM_GPUS_PER_NODE \
--rdzv_id=$SLURM_JOB_ID \
--rdzv_conf=is_host=\$(((SLURM_NODEID)) && echo 0 || echo 1) \
--rdzv_backend=c10d \
--rdzv_endpoint='$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)'i:29500 \
$TRAINING_CMD"
elif [ "$DIST_MODE" == "deepspeed" ] ; then
echo "DEEPSPEED training: $TRAINING_CMD"
MASTER_ADDR=$(scontrol show hostnames "\$SLURM_JOB_NODELIST" | head -n 1)i
export MASTER_ADDR
export MASTER_PORT=29500
srun --cpu-bind=none --ntasks-per-node=$SLURM_GPUS_PER_NODE --cpus-per-task=$SLURM_CPUS_PER_GPU \
python -u $TRAINING_CMD --deepspeed
# # Run with deepspeed launcher: set --ntasks-per-node=1
# # https://www.deepspeed.ai/getting-started/#multi-node-environment-variables
# export NCCL_IB_DISABLE=1
# export NCCL_SOCKET_IFNAME=eth0
# nodelist=$(scontrol show hostname $SLURM_NODELIST)
# echo "$nodelist" | sed -e 's/$/ slots=4/' > .hostfile
# # Requires passwordless SSH access among compute node
# srun --cpu-bind=none deepspeed --hostfile=.hostfile $TRAINING_CMD --deepspeed
# rm .hostfile
elif [ "$DIST_MODE" == "horovod" ] ; then
echo "HOROVOD training: $TRAINING_CMD"
srun --cpu-bind=none --ntasks-per-node=$SLURM_GPUS_PER_NODE --cpus-per-task=$SLURM_CPUS_PER_GPU \
python -u $TRAINING_CMD
else
>&2 echo "ERROR: unrecognized \$DIST_MODE env variable"
exit 1
fi