Defining machine learning workflows
Author(s): Matteo Bunino (CERN), Killian Verder (CERN)
Pipeline for sequential workflows
For simple workflows, itwinai defines a Pipeline, defined as an array or dictionary of ordered components. Much like a python notebook, the Pipeline sequentially runs through the user-defined components inside of it, ensuring code legibility and organisation. The pipeline execution also avoids I/O overheads typical of serialization of intermediate results to storage when moving to the next component, ensuring efficient workflows.
The pipeline structure handles component connection by passing preceding components’ output into following components’ input whilst staying in-memory, similarly to scikit-learn’s Pipeline. This also implies that the Pipeline structure only handles sequential workflows; more advanced (Directed Acyclic Graphs or DAG) can be implemented with alternative methods as explained in the section DAG Workflows.
A Pipeline can be directly defined in Python code but can also be fully represented in a configuration file. The configuration file contains all the parameters and structure variables to uniquely identify any Pipeline and is saved as a .yaml file. This files contains all the parameters and structure variables required to uniquely identify a Pipeline.
Crucially, the input(s) for a component must be appropriate for that component. Pipeline execution occurs in the order defined by the user. Thus, the output of a component must be suitable for the input of the following component. The Adapter component can be used to ensure this. It takes any number of inputs and will output some or all of those inputs in a user-specified order.
Below you can find an overview of each component.
Pipeline components
Components are defined as discrete steps in a Pipeline and implemented as Python classes. For each pipeline component, an execute() method is defined that provides a unified interface with every component as well as the whole pipeline.
Components provide the structure in which user’s python code can be easily integrated and deployed for DDP. These components are ‘empty’; users have total freedom in how to implement each component, after which the Pipeline wrapper ensures DDP deployability.
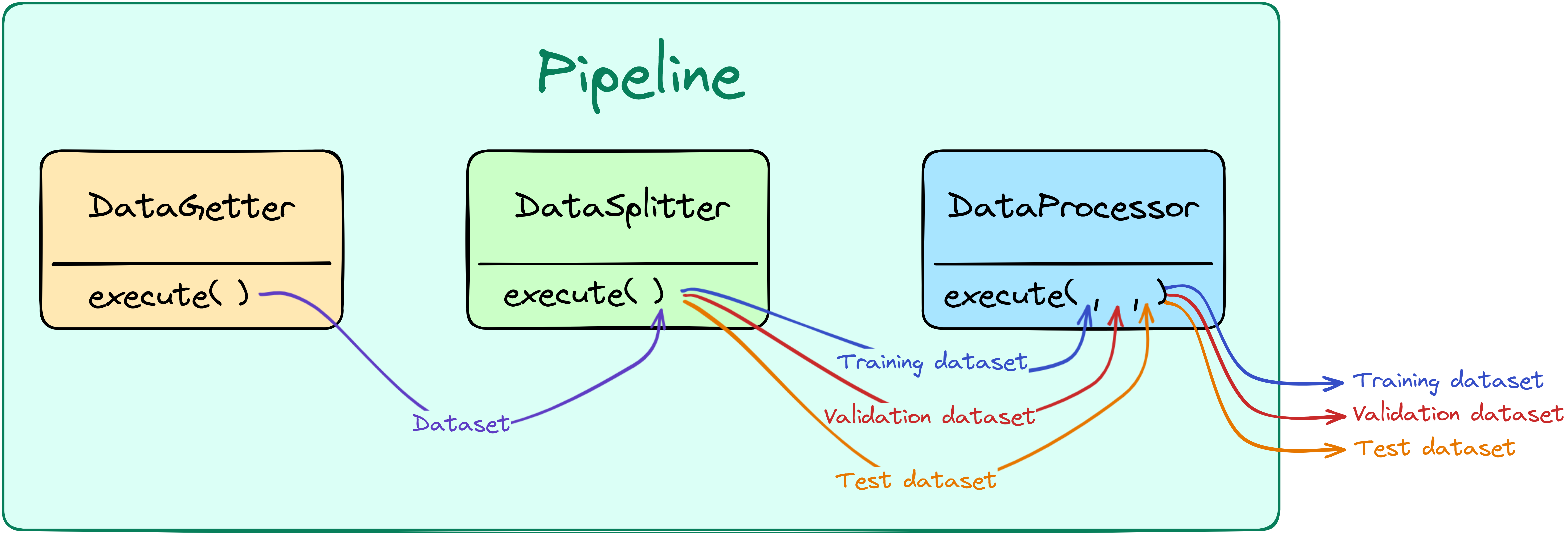
DataGetter
This component gets or loads the data from a given source and passes it on to the next component. Its execute() method therefore takes no input and passes on the dataset as a single output. This component sits at the start of the Pipeline and is usually followed by a DataSplitter component.
The method of loading data is user-defined; the DataGetter component provides the needed structure to integrate into the Pipeline structure. As such, the user is unconstrained in terms of dataset format, structure, or size.

DataSplitter
The DataSplitter component splits a given dataset into three outputs following a user-defined split ratio. These three outputs will be passed on and used as train, validation, and test sets. The splitting method is defined by the user.

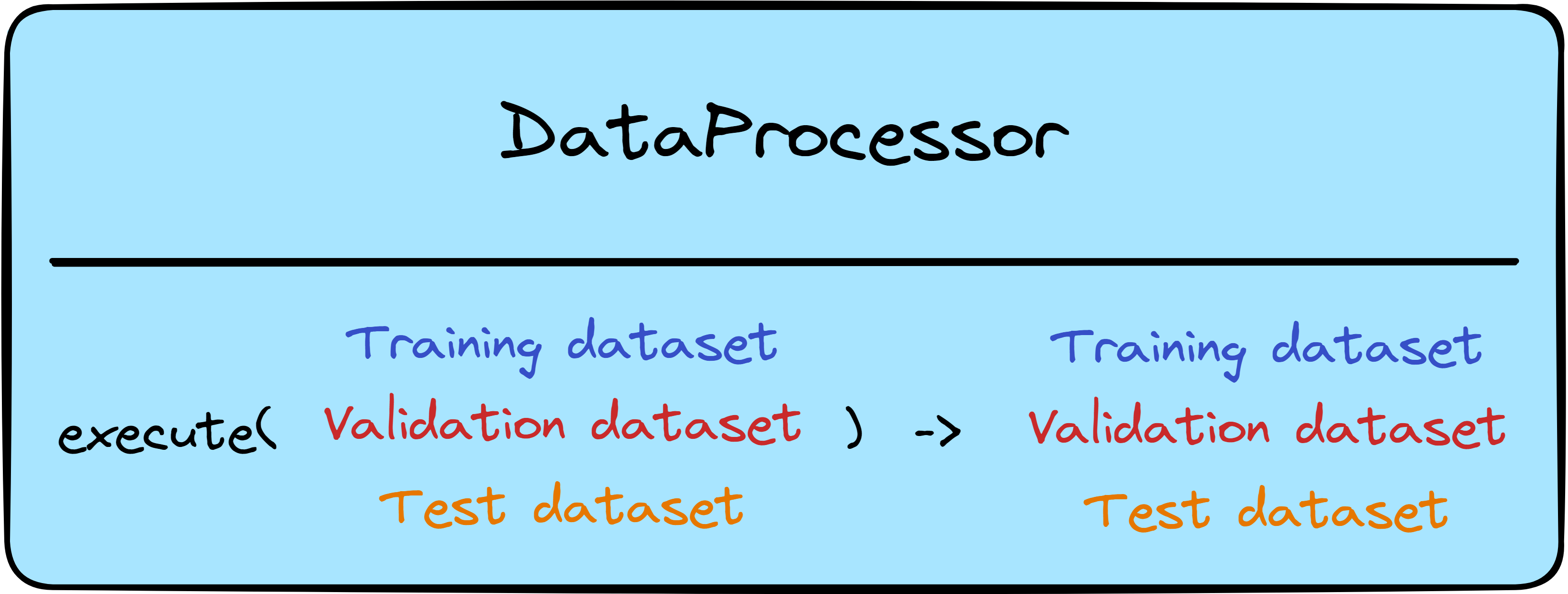
DataProcessor
The DataProcessor component is used for data preprocessing. It is worth noting that data preprocessing before the DataSplitter component is not feasible with this component as it assumes the data to already be split into train, test, and validation sets. This assumption is made to avoid the introduction of bias or skew in the data, which may happen when preprocessing data before splitting it. However, as the components leave the implementation method undefined, there is no preprocessing requirement.
Trainer
The Trainer component covers the actual model training. Taking train, test, and validation datasets as inputs, the Trainer returns its input as well as the final trained ML model for further use.

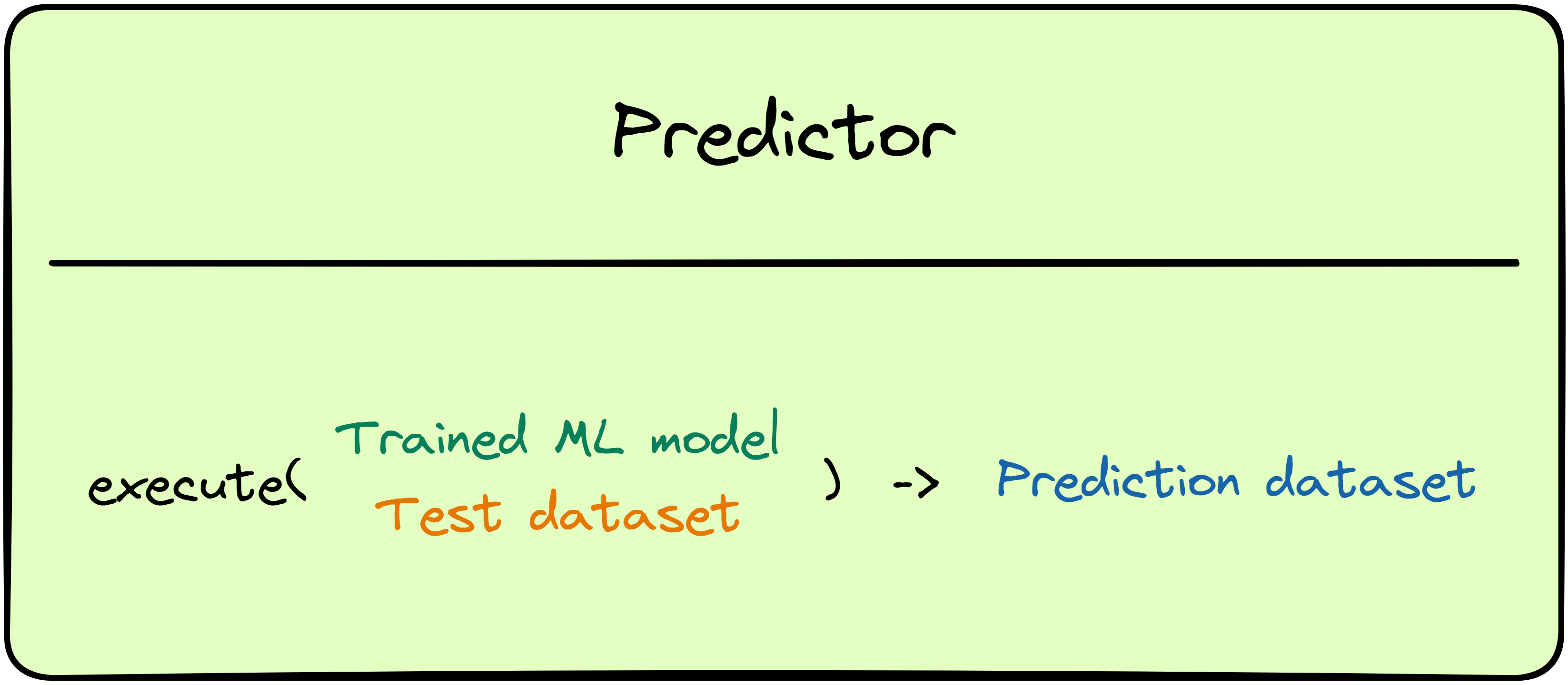
Predictor
In order to gauge the performance of the trained model, the Predictor component receives the trained model and the test dataset as input, then outputs a prediction dataset for that model.
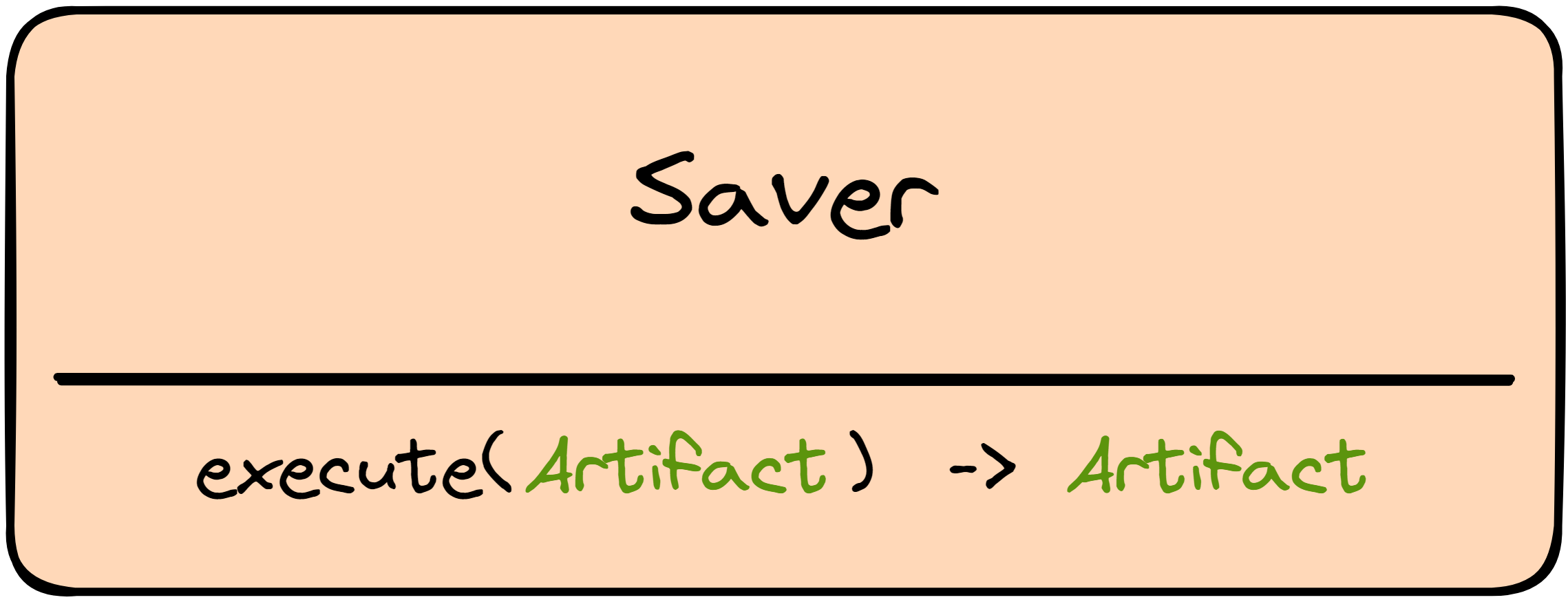
Saver
The Saver component receives as input an element, saves it to storage following the strategy implemented by the user, and returns the same value received as input.
Adapter
The Adapter component gives the user a lot of flexibility in component arrangement. It takes any number of inputs and can output any number of them in any order. Since this component only selects and rearranges the given inputs, there is no restriction on number or format of inputs. The user then defines which inputs they want passed on and in what order these should be passed on.

An example of this is shown in the diagram below. In this case, the Adapter component receives three inputs. The user defines the component’s policy, which describes what the output will look like. In this example, the user decides that input_arg0 is not needed. By excluding input_arg0 from the policy, the first input is not passed on. The order of input arguments in the policy defines the order in which the inputs are passed through. In our example, the user decides they want to output the second input first. Thus, the policy becomes [input_arg2, input_arg1]; leaving out the first input and naming first the third, then the second inputs in the policy gives us the desired output seen in the diagram.

Warning
The Pipeline structure does not handle improper inputs for its components! Each component expects predefined inputs which should be taken into account when constructing your Pipeline. The Adapter component can be used to ensure components receive the correct input if the preceding component’s output is unsuited. For example, DataSplitter returns three data arrays whereas Saver only takes one input argument. To save after a split, Adapter can be used to select the element to be saved by Saver.
Simple Pipeline Example
The figure below shows a diagram of a simple pipeline structure, using only the DataGetter, DataSplitter, and DataProcessor components. As the output of each component is suited to the input of its following component, they can be packaged sequentially in a Pipeline wrapper. Upon execution, each component will run in turn and automatically pass on its output as input to the execute() method that each component interfaces through.
Tutorials on the itwinai Pipeline
DAG Workflows
Below you can find an example of a DAG workflow, in which the sequential Pipeline is replaced with a graph of itwinai Components.